尊龙凯时中国官方入口 算力即收入: 黄仁勋2026台北GTC演讲, 完整版来了


作家|林易
剪辑|重心君
6月1日,在2026年的英伟达GTC台北大会上,黄仁勋用一句话定调了AI行业的新范式:
AI还是从单纯回应问题的大言语模子阶段,认真跨入或者自主不雅察、推理、计议并调用器具的Agentic AI期间。
在黄仁勋看来,智能体正在澈底转换传统的蓄意模式。畴昔咱们习气于运行传统操作系统中的软件,而咫尺的应用形态还是变成了由大模子、禁止外壳、器具和运行时共同组成的溜达式系统。
这种全新蓄意模式的出现,意味着从底层的云霄数据中心,到用户每天面对的PC电脑,再到企业级软件和物理宇宙的机器东说念主,总共这个词科技行业的软硬件架构王人需要迎来一场深度重构。
这场发布会中,英伟达的总共新品,王人在为一个计划办事:让海量的智能体在云霄、个东说念主电脑、企业办事器以及机器东说念主体内,以更低的延迟、更低的成本高效运行。
因为在智能体期间,算力即收入(Compute is Revenue)。
咱们整理了本次发布会四大核心居品矩阵的要道信息,以下是重心内容:
1. RTX Spark平台与N1X芯片:重构PC,开启端侧智能体期间
在端侧,英伟达与微软联手打造RTX Spark平台,重构PC形态。
RTX Spark是兼容Windows与CUDA的全新址品线,涵盖条记本、台式机以及责任站。对于普通用户,它将成为一台24小时在线、免调用费的私东说念主智能核心,随时接收东说念主们的数字生活。
驱动这一平台的是英伟达与联发科合作打造的N1X芯片。它接纳台积电3nm工艺,单芯片封装了具备6144个CUDA核心的Blackwell RTX GPU(AI算力达1 Petaflop),集成了20刚毅制版Grace CPU,并配备了高达128GB的融合内存。
RTX Spark与N1X芯片买通了高负载端侧AI的终末一公里。不管是高帧率好意思满因循快节律的FPS与重度开放宇宙生计游戏,如故在游戏后台以毫秒级反馈腹地Agent的推理苦求(竟然时自动代码查验、自动三维建模渲染等),它王人能松懈胜任。
异日的PC不再是点击运行软件的机器,而是私东说念主专属的数字机器东说念主,在保护用户阴私的前提下,深度整合跨应用的数据和责任历程。
2. Vera CPU:为智能体打造的超算工场大脑
传统的CPU是为东说念主类的指示习气遐想的,而Vera CPU则是首款专为衰退镇静、条目极低延迟的智能体打造的处理核心。
Vera CPU配备了88个Olympus核心,单核具备惊东说念主的10条指示索求性能。搭配LPDDR5X内存(1.2 TB/s带宽),且芯片里面完结了3.6 TB/s的无损互联荟萃,澈底处置了AI数据中心里GPU高频闲置恭候CPU处理逻辑的严重瓶颈。
包含Vera CPU的Vera Rubin多机架级(pod-scale)智能体超算平台咫尺已全面进入量产阶段。
极低延迟换来的极高蒙眬量,平直拉高了单瓦特或者生成的Token数目。在真实业务中,Vera CPU的智能体沙盒性能是传统x86的1.8倍,SQL数据库查询速率提高3倍。这不仅是本事的得手,更是为云厂商和AI企业构建的最低Token坐褥成本的护城河。正如黄仁勋所强调的,在异日,数据中心将成为坐褥Token的AI工场。
3. Neotron 3 Ultra模子与NVIDIA Agent Toolkit器具包:企业级AI的操作系统
为了让企业或者安全、高效地部署智能体,英伟达发布了全新开源基础模子Neotron 3 Ultra。
Neotron 3 Ultra在业内率先接纳了SSM(景色空间模子)与MoE(羼杂行家模子)的复合架构。在性能上,运行速率比拟传统大模子平直飙升5倍,推理成本大幅压缩30%。
同期,英伟达还推出了企业级AI器具包NVIDIA Agent Toolkit。这套器具包是英伟达向企业端抛出的营业变现杀手锏。高度依赖内容分发、精确告白产运以及复杂业务流自动化的企业,咫尺不错在保护核心营业数据的前提下,低成本特有化部署完全懂里面业务的超等智能体矩阵。AI将确凿下千里到每天的营业活水线中干活。
4. Cosmos 3模子与Isaac Groot机器东说念主:物理AI的新打破
Cosmos 3宇宙模子是一款羼杂Transformer架构模子,或者将蓄意机合成的视频、动作和言语转动为机器东说念主能平直学习的第一东说念主称物理法例。
Isaac Groot参考遐想由Jetson Thor平台驱动,领有31个躯干开脱度和双侧各25个开脱度的高精度Sharpa机械手,为斟酌东说念主员提供了一个开箱即用的强劲平台。
通过Cosmos 3和虚构孪生平台的大范围合成数据喂养实体躯干,东说念主形机器东说念主走出实验室,进入大范围应用的表面与工程基石认真成型。这将转换工业制造、物流致使家庭办事等范围的异日图景。
从底层的Vera CPU,到端侧的N1X芯片,再到企业级的Agent Toolkit和物理宇宙的Cosmos 3,英伟达的2026年全线居品发布,明晰地勾画出了一幅以Agentic AI为核心的异日蓝图。在这场算力与智能的革射中,那些或者最高效地生成和期骗Token的企业,将掌捏通向异日的钥匙。
以下是黄仁勋2026台北GTC演讲实录:
1. 实用AI期间开启,智能体AI重塑坐褥力
迎接来到GTC Taiwan。很惬心见到大众,回家真好。我此次把父母也接回了家,请大众为我的父母,以及咱们赛前扮演的台湾超等巨星们饱读掌。今天现场观者云集,咱们同期正向全台湾其他70个不雅影派对同步直播这场主题演讲。
今天有许多内容要与大众共享,也有许多合作伙伴需要感谢。咱们在台湾的生态系统范围还是发展得极其庞杂,令东说念主难以置信。东说念主们平常以为生态系统即是咱们的软件栈,或是构建在NVIDIA蓄意系统之上的开发者生态系统。但NVIDIA的生态系统其实朝上蔓延到了咱们在台湾的总共供应链,那是万物肇始之地,向下则一直蔓延到数据中心并最终触达终局用户。
今天咱们将推敲这总共这个词生态系统。台湾领有宇宙上最丰富、最顶尖的供应链生态系统。这里有相配多优秀的公司和我最可爱的生态合作伙伴,有太多东说念主需要感谢。相配感谢大众的光临。
本年咱们的业务正在以惊东说念主的速率共同增长,听说台湾的年度GDP也将增长近10%,这简直不可想议。两年前我在这里谈到AI将从生成式AI演进到其他形态。如今下一波波浪智能体AI(Agentic AI)还是到来,这也美艳竟然用AI期间的认真开启。
这意味着什么?以GitHub为例,软件编程是智能体AI首批落地的应用范围之一。这是一个极具价值的劳动,全球有三四千万名专科软件开发东说念主员以此营生。在GitHub上,开发者下载软件并进行修改,然后将代码推送且归(commit)。2023年的commit数目是3亿次,2024年是4亿次,2025年是5亿次。而在2026年的前几个月里,这个数字简直增长了三倍。
这三千万软件开发东说念主员每年约有3万亿好意思元的薪资开销,因循起了全球100万亿好意思元范围的产业。如今这3万亿好意思元的薪资创造了近三倍的产出,异常于完结了9万亿好意思元的坐褥力,这种差距是惊东说念主的,这恰是AI的后劲与高兴。
有东说念主说AI会减少责任岗亭,这完全是一片胡言。履行上软件工程师的数目正在加多。原因很肤浅,如果聘用别称软件工程师能产生价值9万亿好意思元的坐褥力,企业诚然会想要雇佣更多东说念主。这种惊东说念主的产出很快就会在经济中体现出来。从行业角度来看,实用AI的到来意味着当前对Token的需求量极大。因为Token咫尺还是成为了盈利和收入的单元,AI公司渴慕生成更多的Token并建设更多的AI工场。这恰是台湾算力需求飙升的原因,亦然诸君业务焕发、股价飞腾的能源。
蓄意模式还是澈底转换。实用的AI还是到来,它咫尺是利润与GDP的生成器。其背后是一种全新的蓄意模式,不再只是是大言语模子,更是智能体(Agent)。
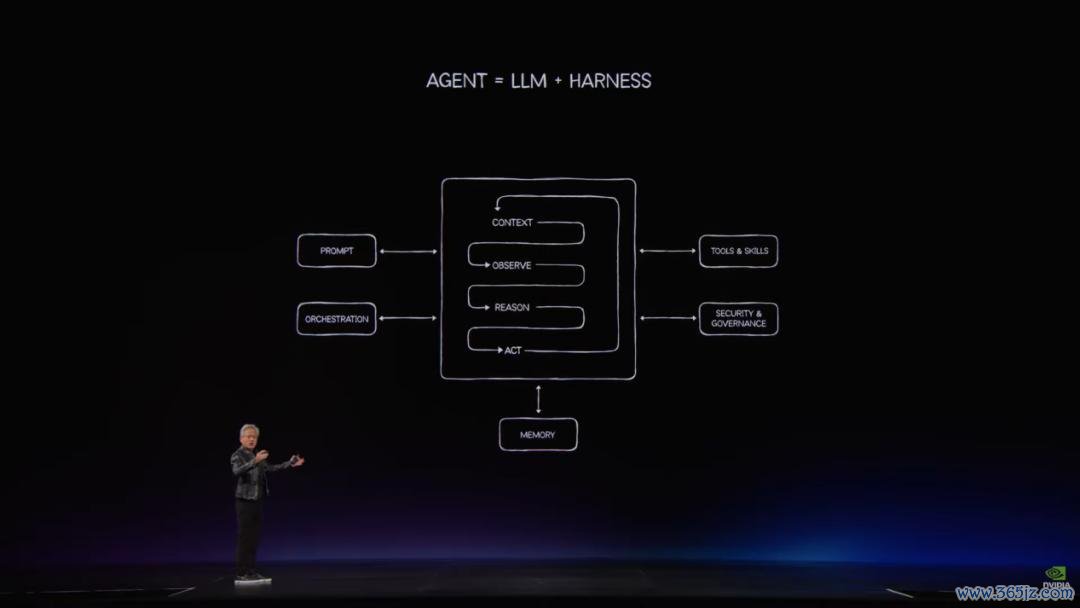
传统意旨上咱们在操作系统中运行应用范例和代码。而今天的新模式是运行在容器框架(Harness)中的智能体,它由一个或多个大言语模子组成。这个框架机制负责指点和编排AI开展高效的责任。
当接收到输入时,智能体必须进行知道、不雅察、推理和行径,并调用诸如电子表格、Web浏览器或数据处理引擎等器具。总共这个词过程是受软件编排的,框架负责路由信息,处理高下文,知道近况,进行推理并制定施行计划。本质上这即是智能体的责任旨趣。它像东说念主类一样处理短期责任牵挂和恒久牵挂,因此内存料理系统变得极其紧迫。在这个新模子中,大言语模子负责想考,而外壳范例则像操作系融合样将一切贯穿起来。
这是一个要紧的打破,大言语模子咫尺还是或者相配出色地进行想考、推理、计议和使用器具。并吞内存料理框架和器具编排,咱们咫尺不错成就不凡。举例给出一句提醒词,AI就能生成完整的代码。咱们咫尺使用的是Claude Code,但Codex的阐扬也相似出色。再比如输入“创建一个GIF在玄色散点图上娇傲NVIDIA绿色的点从台北101大楼变形为GTC Taipei 2026再变形为NVIDIA眼睛图标然后散射近似”,AI就能平直生成动态图。致使当你弄丢遥控器电板盖时,只需提供图片并让AI创建一个准备好进行3D打印的CAD文献,它就能调用器具完成制作。这即是全新的蓄意模式。
畴昔咱们需要启动应用范例进行点击和输入,咫尺只需向AI讲解咱们的意图和需求,AI就会自动生成代码或使用器具产生必要的输出。这是异日蓄意机的责任表情,即智能体AI。咱们为此勤恳了两年,如今它终于化为现实。
咫尺的要紧打破之一在于器具的使用。有东说念主以为AI期间和智能体AI的到来会让总共软件公司倒闭,但事实只怕相悖。未下宇宙将充满智能体,不再受限于东说念主口数目,这些智能体将比以往任何时候王人更常常地使用器具。对软件公司而言这其实是一个绝佳的期间,前提是软件必须以智能体或者调用的表情呈现。
看成NVIDIA的瑰宝,CUDA-X库慎重验着属于它的好意思好期间。今天咱们或者将这些库提供给智能体,它们的使用效用致使超越了东说念主类。20年前咱们构建了用于加速蓄意的单一架构CUDA,重新发明了蓄意。如今上千个CUDA-X库还是成为智能体的器具,助力科学和工程范围的打破。比如用于蓄意光刻的cuLitho、用于决策优化的cuOpt、用于平直寥落求解器的cuDSS、用于跨结构化和非结构化文档深度斟酌的AIQ、用于AI RAN的Aerial、用于可微物理的Warp,以及用于基因组学的Parabricks。这些精妙算法的基石是璀璨的数学。

2. 全新蓄意模式:大言语模子与器具的协同编排
软件的蓄意模式行将转换,智能体代表着终极的解耦式溜达式蓄意模子。为了运行智能体,数据中心内各个位置的繁密蓄意机将被激活。智能体由模子、框架、器具、手段和运行时组成。你不错把模子遐想成大脑,把框架和运行时的器具遐想成身段和责任车间。这是一个在车间里熟练使用器具的工东说念主,这一切王人在极大范围下进行,溜达在蓄意机的不同部分。大言语模子负责想考、处理高下文、不雅察环境、推理并制定施行计划。每当模子进行想考时,整架Grace Blackwell NVLink-72就会被激活。而每当它使用诸如C编译器、Python、JavaScript或加速蓄意等器具时,就会消耗CPU资源。
今天的智能体如故肤浅的器具使用者,但来日它们将变得相配闇练。这恰是CUDA-X库备受智能体怜爱的原因。咱们的总共CUDA-X库咫尺王人具备了AI不错学习并使用的技高手册。AI阅读后便能意会使用措施,其操作这些库的能力将令东说念主惊奇。这些器具运行在CPU、GPU和大言语模子之上,而安全框架则运行在CPU和NVIDIA BlueField DPU等安全处理器上。总共这个词责任历程的编排王人由CPU完成。
其中最顾惜的武艺之一是内存料理。责任牵挂不错被肤浅知道为KV缓存(KV Caching)。系统不仅需要进行数据压缩,还要处置复杂的检索问题,即何如检索结构化和非结构化数据,以及何如梳理不同数据间的实质关系。这个处理过程极其复杂,AI的内存系统必将激勉存储系统的澈底变革。
这种全新的智能体应用和蓄意模式与传统的应用范例运行表情截然有异。畴昔软件平常封装在单一二进制文献中并运行于操作系统内。而咫尺边对这种解耦的、溜达式的异构蓄意需求,咱们构建了下一代居品Vera Rubin。
Vera Rubin不仅是一颗芯片或一个GPU,它是一个令东说念主惊奇的端到端系统。它配备了GPU和Vera Rubin NVLink-72,由Vera CPU进行编排,并领有立异性的存储系统。并吞CX9和DOCA软件栈,系统内置的安全处理器确保总共静态、传输中及使用中的数据王人经过加密。由于AI模子极其稀少,总共这个词系统严格受命巧妙蓄意(Confidential Computing)的模范。
Vera Rubin是咱们公司历史上最广宽的职业,全公司繁密部门的工程师王人为此倾注了心血,在座的许多合作伙伴也参与了总共这个词系统的创建。Vera Rubin是一个超越芯片办法的古迹。NVIDIA早已从一家GPU公司演变成一家系统公司,遐想出了史上最复杂、最澈底的系统。
但归根结底,咱们的客户不仅想购买蓄意机,他们更想要建造AI工场,这亦然NVIDIA再次自我转型的核心原因。如今咱们的本事和合作伙伴王人已彭胀到了基础设施层面。发电机、冷却系统和电网供应商等繁密工业公司成为了咱们生态系统的一部分。咱们正在构建一个全栈系统,助力客户打造非常的AI基础设施。
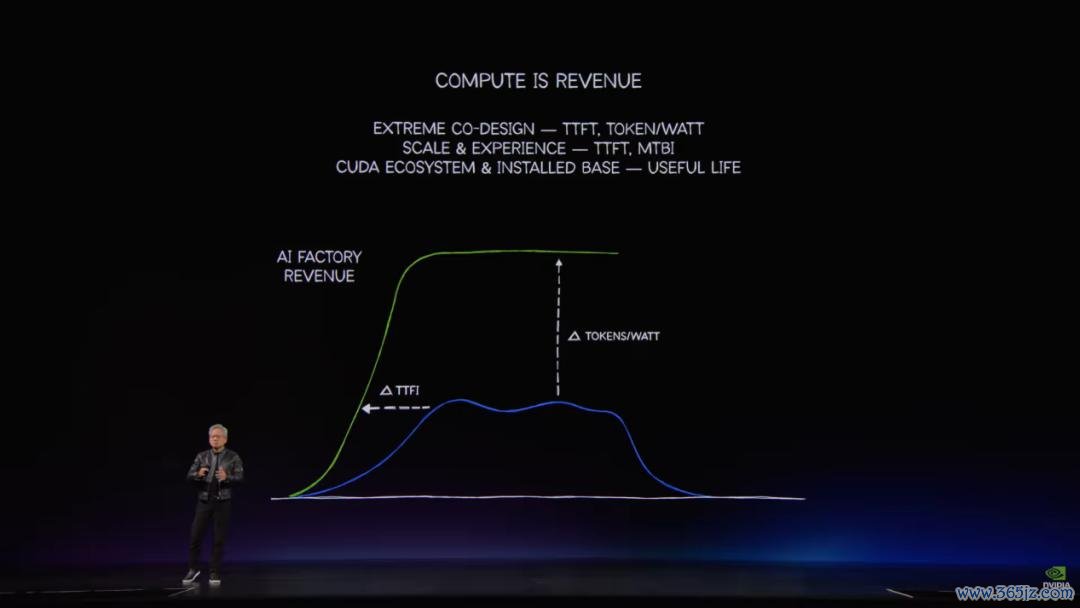
当前全球正竞相建设AI工场,这是东说念主类历史上范围最大的基础设施建设。AI工场的每一层包括芯片、机架、荟萃、电力、冷却和电网,王人必须进行端到端的协同遐想,因为在这里算力就等于营收。
NVIDIA DSX恰是用于高效、盈利地构建和运营AI工场的蓝图与参考遐想。一切从DSX SIM启动。借助DSX SIM Omniverse蓝图,合作伙伴在首个机架落地前,豪门国际官网娱乐网就能在数字孪生中计议布局、模拟电力与冷却系统、遐想荟萃并考证总共变更,从而完成Vera Rubin AI工场的遐想与考证。
工场启动后,DSX OS将接收并负责设立、运行、监控和拓荒基础设施,将硬件转动为确凿、弹性且AI就绪的多佃户算力资源。当前的AI工场在电力设立上频频过度预留高达40%,而DSX Max LPS让运营商或者在同等电力预算内安全部署更多GPU,每年可加多数十亿好意思元的收入。打破性的45摄氏度高温液冷本事贬低了水电消耗,将更多电力用于产生收入的蓄意。动态功率分派本事在机架间调理电力,回收闲置功率并运输至高负载区域,同期平滑本事能有用遏制峰值电流尖峰和功率浪涌。
在总共这个词工场中,AI智能体团队与DSX Max LPS协同责任,及时均衡冷却与功耗。此外,DSX AI工场是或者与电网协同运行的机动能源钞票,DSX Flex不错读取及时电网信号,在电网承压时动态调养工场功率。异日十年内,将稀奇百吉瓦(GW)范围的AI工场参预运行,NVIDIA DSX AI工场将以最高效用生成成本极低的Token,同期增强电网的贯通性。
畴昔的蓄意生态系统中,NVIDIA的软硬件蓄意层被集成到第三方平台中办事终局市集。但如今咱们面对的是一个AI工场生态系统。NVIDIA的业务向下贱蔓延到了总共这个词基础设施生态,不仅制造GPU和系统,更致力于匡助客户建设极其复杂的AI基础设施。
一座一吉瓦(GW)范围的AI工场,造价曾是两三百亿好意思元,咫尺已达五六百亿好意思元,很快就会攀升至一千亿好意思元。上千亿好意思元参预的工场必须在首次运行就获得得手独立即奏效。
面对如斯不菲的成本成本和顶点的复杂性,咱们期骗Omniverse完成了这一切。畴昔咱们是在蓄意机里遐想芯片和模拟系统,而咫尺在破土动工参预真金白银之前,咱们就能在Omniverse的数字宇宙里构建纵情范围的庞杂系统。
这即是咱们被称为DSX的生态系统,RTX代表GPU,DGX代表系统,而DSX则代表基础设施。凭借涵盖软硬件的全栈本事能力,咱们匡助许多也曾的小公司成长为了宇宙级的AI云。
举例CoreWeave咫尺的估值已高达数百亿好意思元且增长迅猛,Nebius也相似保持着惊东说念主的增速。这些云办事商领有许多隆起的客户,如编程器具Cursor、图像生成公司Black Mountain Labs、World Labs、Revolut以及Shopify。其他区域如英国的Nscale正在办事英国电信和Google,韩国的Naver Cloud在办事韩国银行和当代汽车,印度的Yotta、新加坡的AI Singapore、印尼的Indosat,以及台湾的GMI王人在为区域乃至全球客户提供非常的AI办事。
滚球app中国官方网站AI将无处不在,每个地区、每家公司王人将由其驱动。建立AI云不仅需要NVIDIA底层的硬件、软件、库以及全球开发者生态,更需要应付AI工场基础设施在资金和钞票层面的庞杂复杂性。正因如斯,NVIDIA得手转型为AI基础设施公司。
3. 构建AI工场生态:推出端到端Vera Rubin系统
匡助客户构建和部署AI工场至关紧迫,因为在今天算力即是收入,算力即是利润。一座斥资数百亿乃至上千亿好意思元的基础设施,其上线速率、蒙眬量、可靠性和使用寿命平直决定了企业的命悬一线。
NVIDIA之是以辱骂常的合作伙伴,是因为咱们具备全集成的能力。咱们并非望梅止渴,而是躬行参预数十亿好意思元构建并贯穿了总共这个词基础设施,确保一切运转精采。通过极致的协同遐想与全系统模拟,咱们在首个Token生成时期(Time to First Token)、首次推理时期以及检会启动速率上王人处于宇宙跳动水平。
更紧迫的是咱们的每瓦蒙眬量和每瓦Token数十足是宇宙一流的。如果你的数据中心唯唯一吉瓦的容量,那么在功率上限锁定的情况下,每瓦特的蒙眬量就等于你的平直收入,因为每一个Token王人是盈利的。异日算力即收入,每瓦性能即收入。只是因为芯片价钱低廉就采纳异常的架构是绝不测旨的。必须确保每瓦特营收的最大化,买得越多赚得越多。
第三是可靠性。参不雅数据中心会发现其中稀奇百万根电缆和举止部件,让这些蓄意机和谐运转且保持极高可靠性的概率极低,这极其顾惜。咱们已在大范围环境下运行多时,蓄积了至关紧迫的教悔,尤其是拉长中断间的平均时期。
此外系统寿命面对巨大挑战,因为软件在不停迭代。四年前的Hopper架构期间和六年前的Ampere架构时期,AI还是发生铺天盖地变化。从率先的CNN到Transformer,再到羼杂行家模子,如今咱们步入了智能体系统期间。
软件行业每隔几个月就会浮现新本事。如果架构不够机动生态不够丰富,就无法历久应付这种发展弧线,难以展望系统寿命。但NVIDIA的系统遍布全球,开发者从CUDA起步,使得系统生命周期和生态钞票或者延续更久。龟龄命钞票意味着极低的总体领有成本,这即是咱们的核心上风。由于大众对盈利性AI的需求极其旺盛,算力成为咫尺的瓶颈。因此咱们将负重致远,匡助宇宙各地建立AI工场。
我相配惬心肠晓谕,Vera Rubin现已全面参预量产。咱们为Vera Rubin建立的供应链范围是Grace Blackwell的两倍。畴昔拼装一个Grace Blackwell机架需要两小时,咫尺只需五分钟。这不仅大幅提高了产能,蒙眬量也显赫加速,以得志庞杂的市集需求。
大言语模子用于生成谜底,而智能体AI处理的则是完全不同的问题。智能体需要不雅察推理计议并使用器具,料理海量高下文和短恒久牵挂,致使能按需启动子代理。NVIDIA Vera Rubin恰是专为处千里着沉着能体AI打造的多机架级系统。从第一代DGX-1到如今的Vera Rubin,咱们不停挑战芯片和系统的极限。组成Vera Rubin的七颗全新芯片由TSMC接纳3纳米工艺、CoWoS封装本事以及HBM4内存制造。单块蓄意板集成六万亿个晶体管。Vera Rubin MVL72负责推理计议和高下文知道,接纳无电缆原位制造和液冷本事,完结AI工场范围下的极高韧性。
同期推出的Vera CPU机架集成了256颗液冷CPU,专责模子编排与器具启动。在Foxconn和Quanta,尊龙凯时中国官方入口具备极低延迟的Grok 3 LPX正在成型。如果说MVL72旨在完结最高蒙眬量,那么Grok LPX则致力于最低延迟生成。加上处理AI存储与安全的Vera BlueField-4,以及全球首款配备共封装光学器件的以太网交换机Spectrum-X,咱们与台湾供应链共同为AI期间重新界说蓄意。
Vera Rubin不单是是为运行AI而生,更是专为运行智能体系统遐想的超等蓄意机。畴昔咱们打造Hopper主如若为了预检会,其时东说念主们以为推理很肤浅。但羼杂行家模子极其复杂,要在完结高蒙眬量的同期保持极快反馈相配顾惜。这即是咱们创造NVLINK-72的原因,它让NVIDIA的Token生成成本降到全球最低。如今Vera Rubin超越了单纯推理,主导智能体系统中的推理任务。总共这个词系统甩掉了叨唠电缆,可靠性达到前所未有的高度。除了强劲的蓄意和存储托盘,Vera Rubin还配备了立异性的NVLINK交换机和横向彭胀的以太网交换机,如今NVIDIA还是成为全球最大的荟萃公司。

4. 专为智能体遐想:颠覆性处理器Vera CPU
接下来咱们要谈谈专为AI期间打造的Vera CPU。迄今为止的总共CPU王人是为东说念主类遐想的,按秒计费按核心出租。但智能体不同于东说念主类,它们衰退镇静,生活在以纳秒为单元的宇宙里。智能体在调用器具或考核数据库时,任多么待王人会遏抑下一步行径,因此极低的CPU延迟至关紧迫。
为完结极致交互,咱们创造了Vera CPU。在Vera Rubin机架中,CPU负责编排GPU料理缓存以及处理安全破损。智能体正以惊东说念主速率考核内存,存储办事器和CPU已成为数据中心肠能的要道瓶颈。AI工场的核心经济价值在于不停生成Token,绝弗成让CPU成为遏抑。因此咱们从零启动,专为智能体构建了全新架构。Vera CPU不仅具备十足顶尖的单线程性能,每时钟周期可施行十条指示,其数据蒙眬带宽也达到宇宙顶级水平。
智能体系统本质上是解构且溜达式的,核心与存储、GPU之间的数据传输速率是要道。Vera CPU的贯穿织网传输速率达到光速级,是首款维持PCIe Gen 6和LPDDR5X内存的处理器,总带宽3倍于传统CPU。异日将稀奇十亿智能体高频调用资源,为了不霸占生成Token所需的电力,Vera CPU在保持高性能的同期完结极高能效比。这四大属性使其在真实单线程性能上远超现存最高性能的x86处理器,完结史无先例的性能飞跃。
智能体期间澈底转换了CPU的脚色。如果把GPU比作管弦乐队,CPU即是率领家。传统的按核心切片虚构化模式已成为限定GPU期骗率的瓶颈。Vera接纳NVIDIA定制的Olympus核心和可彭胀一致性架构,成心针对数据中心责任负载、分支密集型Python运行和沙箱代码施行进行优化。通过神经分支展望器和大型乱序施行引擎,Vera确保指示延续高效流动。它还能在不糟跶带宽的前提下校正多个内存异常,大幅贬低延迟。
借助第二代可彭胀一致性结构,Vera的核间通讯速率比传统CPU快50%。它通过NVLink将GPU平直贯穿到荟萃架构,提供了近两倍于x86的智能体沙箱性能。每一家开展AI业务的公司王人已对Grace进行认证并优化了软件栈,而Vera将无缝剿袭这一庞杂生态,成为全球优化进度最高的智能体CPU。在履行性能评测中,Vera将通用数据库引擎SQL的运行速率提高了惊东说念主的三倍。这款专为智能体期间打造的CPU,必将成为咱们新增长引擎。
下一个是及时流处理。记取你的AI将不单是是阅读文档,它还会监测遥测数据,止境是在工场或证券交游所里面。涌入的数据脉冲会进入CPU。
Vera CPU正在为New York Stock Exchange运行及时流处理。其主席Lynn Martin一直相配鼓动地与咱们合作。Vera CPU提高了六倍的性能,全是因为单线程指示施行带宽以及核心里面和外部的带宽。Vera是澈底的立异性居品。平常X因子是推敲GPU时才会评论的东西,很少有东说念主会在与CPU联系的真实负载上评论它。我为团队感到自爱,你们作念得太棒了。咱们行将推出一份不凡的道路图,简直总共东说念主王人在振作地维持Vera。
这是Vera开放的开端,它开辟了一个全新的市集。智能体是一种全新的责任负载。畴昔咱们为东说念主类构建CPU,咫尺咱们需要为智能体系统构建CPU。它们的特点截然有异,是以旧的CPU无法胜任。咱们正在构建数以百万计的Era系统。台湾的ODM、总共OEM以及代理型公司等早期接纳者已与咱们一同进入这个以前从未存在过的新市集。它不会取代旧市集,而是一个全新的面向智能体的CPU市集。因为智能体的数目将远超东说念主类,且它们相配不耐性,是以这个市集笃定会比上一个更大。这即是NVIDIA Vera CPU。
5. 赋能企业AI平台:Agent Toolkit与开源模子Nemotron
核心要点在于这是异日十年的蓄意模式。智能体和禁止框架编排着大型言语模子,每家公司王人将运行这种模式并成为智能体公司。每家公司里面王人将有智能体在运行,他们会毅力到智能体将需要我方的操作系统。企业王人在问该何如安全运行并针对自身责任负载构建智能体,因此咱们推出了面向企业级AI的NVIDIA Agent Toolkit。
回看我畴昔五年或十年的GTC演讲就能看到今天,因为咱们一直在为这一刻作念准备。企业要构建代理即办事或运行代理需要具备四样东西。开头是越灵敏、越快、越低廉越好的大言语模子。
其次你需要一套框架来编排总共这个词历程。第三是自带手段并供模子使用的器具,比如我展示的CUDA-X库,它们将成为异日智能体的神级器具。
终末你需要一个能将一切整合在沿途的操作系统或运行时。这即是NVIDIA Toolkit for Agents。它包含你不错修改的宇宙级开源模子,并能运行来自任何东说念主的惊东说念主代码和智能体。你不错在名为Open Shell的容器中高度安全地运行它。该Shell保护智能体受命安全政策,同期保护阴私、权益和身份。开源的NVIDIA Open Shell正被Red Hat、Canonical和Microsoft等粗拙接纳。
Open Shell运行时已针对无处不在的NVIDIA AI平台进行全面优化,因此你不错在职何云霄、腹地致使设备端运行Open Shell。你领有了器具、库、可修改的模子以及像Open Claw和Hermes这么的智能体框架,咫尺不错在职何场所腹地运行。这四点代表了当代企业的操作系统。
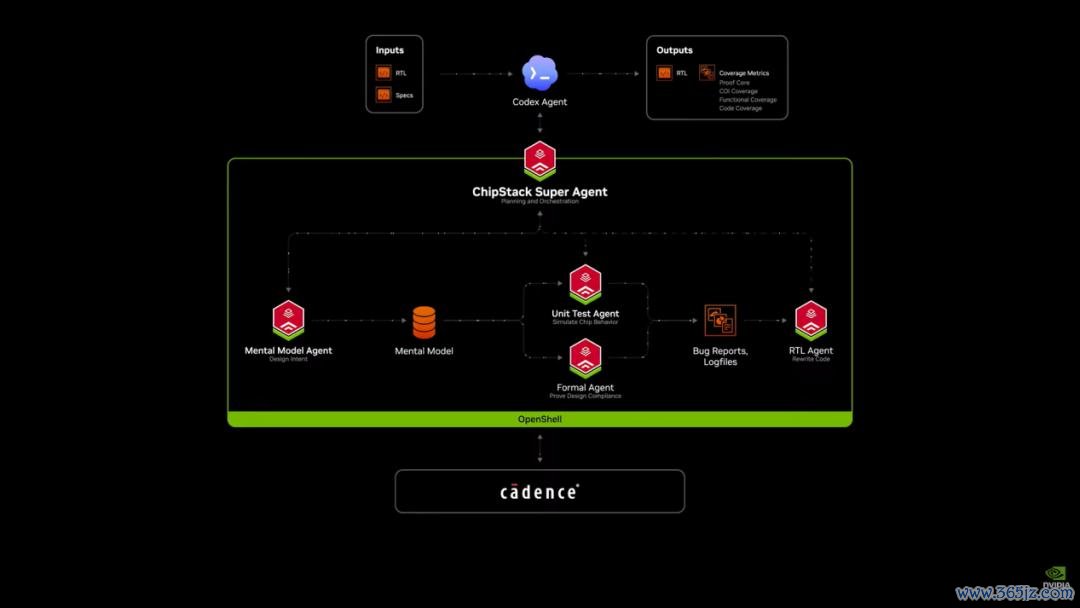
我最可爱的智能体用例之一是芯片遐想师,这是NVIDIA所作念的最紧迫的事情。咱们理所诚然地与Cadence合作,由Codex或Cloud Code编排构建了一个芯片遐想超等智能体。它将RTL、架构图和规格阐发看成输入。咱们共同创建了针对NVIDIA运行时环境并使用Nemotron优化的超等代理。
遐想芯片过火运行系统是极其穷困的工程挑战,包含数万亿个微不雅三维晶体管。每一个栅极和导线必须同步至皮秒级好意思满协同责任。因物理原型速率慢且成本高,工程师在数字范围责任。每颗芯片始于架构范例,随后翻译成芯片遐想言语RTL并在仿真中考证。单一bug能让芯片推迟数月,NVIDIA的数千名工程师每年破耗数十亿蓄意小时运行和调试数百万个测试,该周期平常需数周。为压缩此周期两边构建了遐想考证代理。Codex编排历程,Cadence Chip Stack启动RTL考证轮回,由Nemotron提供能源并由NVIDIA Open Shell确保安全。它调用RTL生成、测试平台创建、追思测试及调试等行家级子代理。
系统自动运行,使用Cadence Excellium进行数百次仿真并用Jasper进行步地考证。揭示遐想颓势并拓荒代码bug后,蓝本数周的责任咫尺只需数小时即可完成,考证周期镌汰至四十分之一以下。NVIDIA与Cadence正期骗AI Agents重塑芯片遐想。咱们将聘用千千万万个Cadence超等代理协同责任,加速公司发展并以更快的速率创造惊东说念主事物。包含模子的器具包期骗了Cadence仿真器和步地考证系统等器具。咱们正与其紧密合作在CUDA上加速总共器具,因为代理需要立即得到谜底。
模子、框架、CUDA加速库、器具及运行时环境交融在沿途。Cadence从非常的模子开赴,期骗其专有常识进行修改和微调,创建出忽闪其责任流的超等代理。这个非常的模子即是Nemotron。
NVIDIA致力于为宇宙构建开放模子以供大众创建专属智能体,今天咱们认真发布Nemotron 3 Ultra。这款极其灵敏的下一代开源模子不仅提供模子本人,还提供总共的检会数据。获利于优秀合作伙伴定约的相互孝顺,Nemotron基于全球最大范围之一的恒久推理、任务处置及器具使用数据集检会而成。
检会剧本和数据已完全向您开放。看成开源模子的巅峰之作和全球跳动的开源模子系统政策,咱们的计划是让您全盘接收并让它为您所用。Nemotron 3 Ultra的速率快了五倍。这是全球首款基于SSM景色空间模子与羼杂行家模子(MoE)的羼杂架构模子。其极快的速率让您能快速想考,在交流成本下想考得更久。与全球最顶尖、最具性价比的开源模子比拟,它价钱低廉30%,总算力和总推理时期成本也低30%。它领有前沿智能且完全开源。咫尺咱们已在开发Nemotron 4.0。
从模子到框架、器具、手段和运行时环境的总共这个词器具包,让全球每家企业咫尺王人有能力创建属于我方的智能体。咱们正与Cadence、CrowdStrike、Solon、Palantir、SAP及ServiceNow等繁密公司合作。东说念主们曾说智能体将颠覆这些市集,但我以为只怕相悖,Agents将为合作伙伴创造有史以来最大的机遇。咱们领有NVIDIA Agentic Toolkit for Enterprise AI来匡助他们。
总结来说Vera Rubin已全面投产,专为新一代Agent打造的Vera CPU也已问世。NVIDIA的企业级AI器具包将让每家企业和软件公司王人能构建Agent。

6. 重塑个东说念主电脑:搭载RTX Spark的PC新纪元
我在台湾的许多一又友和合作伙伴的公司王人是从这里起步的,在许多方面这是当代蓄意机行业40年来的开端。NVIDIA成立33年,咱们出刻下PC行业正处于Windows 3.1期间。Windows 95将PC从企业带出,打形成东说念主东说念主领有的消费电子设备。该蓄意平台的架构遐想恰到平允,系统BIOS、开放芯片组、可贯穿装配的驱动范例以及带有多媒体API的综合层,开启了PC期间,每个元素对PC普及王人至关紧迫。40年后的今天,Microsoft和NVIDIA将重新发明新PC。
明晚我将与Satya潜入探讨咱们共同开展的责任。畴昔三年咱们重塑PC责任表情即是为宽贷这一时刻。智能体不仅在AI云和企业里面运行,也将运行在你的PC上。当PC领有自主智能体时,它能匡助和知道你,你不错与它对话、让它严防你、读取文献并作念斟酌。这个全新操作系统是旧操作系统加上大言语模子。大言语模子是当代版DirectX,它知道提醒词和蓄意机视觉,并能生成音视频。看成PC和智能化的蔓延,当代应用范例已成为一个智能体运行时。
在AI期间重构PC的方针激勉了个东说念主蓄意立异。咱们的个东说念主AI在安全沙箱中延续运行并完成责任,芯片和操作系统必须随之进化。广大推出NVIDIA RTX Spark,咱们将33年教悔浓缩于这颗芯片中。它配备6144个CUDA核心的Blackwell RTX GPU、1Petaflop的AI性能和定制化20核Grace CPU。该芯片接纳TSMC 3纳米工艺和700亿个晶体管,通过NVLINK与MediaTek合作打造,领有128GB融合内存。并吞面向智能体的Windows平台,咱们正重新界说用于创作、游戏及智能体的个东说念主电脑。游戏是咱们最心系的部分,将迎来全新的《极限竞速》和007游戏,同期NVIDIA推出RTX Spark条记本电脑。
这是宇宙上最惊东说念主的芯片,亦然咱们与MediaTek合作打造的讲究芯片N1X,需耗尽33年才能打造出来。因为100%的NVIDIA软件栈王人运行在这里,不管是数字生物学、地震处理、天体物理如故总共CUDA联系的物理、基因组学、AI和蓄意机图形处理王人不成问题。Microsoft和NVIDIA的致密优化使得这台电脑能运行简直总共已创造出的范例以及智能体。
遐想一下,这里的一切王人将在PC上腹地运行Nemotron 3 Ultra或贯穿云霄Claude等模子,创造出惊东说念主效用。每座屋子的遐想王人需要大王人器具和时期,咫尺运行在腹地RTX Spark上的智能体能通过开放式Shell沙箱帮我遐想。它运行Hermes框架并贯穿云霄的Claude Sonnet。我共享办法草图、作风脸色板和提醒词后,智能体便洞开Rhino进行场所建模、塑造地形和建筑体量。它提议有计划并针对成本与舒限定进行优化,随青年景里面布局、墙壁和动线。
我随时可介入调养,门窗和结构元素会自动抛弃,智能体还能检测并拓荒自身异常。批准后智能体将模子完整导出到Blender,并在传输中保持遐想高下文完整。我微调材质后,代理使用带有Flux.1的生成式AI模子在多种光照和视角下将其渲染至像片级真实感。也曾复杂的历程在智能体指点下变得极其肤浅高效。在RTX Spark上进行创作,遐想速率紧随遐想力,这将为总共开发者打造出色的PC智能体体验。
下一个是Adobe。这是一套全球数千万东说念主正在使用的令东说念主惊奇的器具套件。他们重新遐想了Adobe Photoshop和Premiere的核心架构,并将针对RTX Spark发布。它的速率提高了两倍,本人就还是很快了,咫尺速率将再提高两倍。它的遐想对智能体相配友好,通过MCP办事器咫尺不错与条记本电脑上的智能体交互。
繁密客户和合作伙伴对将RTX Spark推向市集感到相配振作。这是40年来首次全居品线的PC变革,每个东说念主王人将维持RTX Spark,共同打造极其智能、强劲且好意思不雅的条记本电脑。
但这还不是全部,RTX Spark是对条记本电脑的重塑。Microsoft和NVIDIA正在重塑总共这个词PC范围,今天咱们将发布一个涵盖台式机、条记本电脑和责任站的全新系列,它们100%兼容Windows,100%维持CUDA,何况100%搭载NVIDIA AI Tensor Core。全球总共在NVIDIA上运行的一切王人不错在这里运行,这是40年来首个完全重新遐想的PC系列。
令东说念主惊奇的还有RTX Spark条记本电脑和台式机居品。这个智能体不错全天候免费运行,你不错下载我方的智能体并让它一直运行。它莫得电量嚚猾,放在家里贯穿着总共这个词房屋的设备,包括条记本电脑、娇傲器、录像头、烘干机、饮水机、滚水器以及安保系统等。这成为了你的个东说念主AI代理,跟着时期推移它会变得越来越灵敏。今天咱们有Nemotron 3 Ultra,异日会有Nemotron 4、Nemotron 5致使6。它在家帮你处理多样事务,比如预订旅行。
如果你想要一个极其强劲的系统,这里有适用于Windows的DGX station。它能运行Windows中的一切,领有768GB内存,不错运行万亿参数模子。它具备20 petaflops算力和每秒8TB的显存带宽,就放在你的办公桌旁。如果你是大言语模子或智能体开发者,把它放在桌边就能提供所需的总共算力,部署时再放入云霄。
追思畴昔,15到20年前咱们有电话的办法,今天咱们有PC的办法。如今你意想手机时,简直会用它作念任何事情,唯一不会用它作念的即是打电话。因此手机对你的意旨与畴昔的电话截然有异。我敢笃定,十年后的PC与你今天所以为的PC将会发生巨大变化,它将不再只是是启动应用或打字的器具。
我完全不错遐想,就像咫尺许多家庭领有家庭影院、大电视、割草机或洗碗机一样,总有一天你的家里履行上会有一台AI超等蓄意机。它运行着你总共的代理和助手,一直为你处理多样事情。你会在家里配备扶直AI智能体蓄意机,跟着时期推移,它们对你来说会变得更像R2D2或C-3PO,而不是一台传统PC。此次对蓄意机的重塑意旨不亚于将电话重塑为智高手机,这是一个全新址品系列的开端。全球100%的PC行业王人已加入咱们共同重塑PC。

7. 迈向物理AI宇宙:Cosmos-3模子与东说念主形机器东说念主
Agentic AI就像数字机器东说念主,或者知道、推理、计议、选用行径并使用器具,它们将在总共蓄意机上运行。
咱们正在研发东说念主形机器东说念主、多样类型的机器东说念主、自动驾驶汽车以及卫星。农业、制造和重工业设备王人将完结代理化,你致使会领有我方的代理助手。异日的基站和无线电台也将是代理化的,它们能了解流量并与其他基站融合以减少能耗,从而提高频谱效用。异日一切王人将运行智能体,将会稀奇千亿个智能体蓄意机运行辞宇宙各地。
最大的挑战是数据,言语模子不错使用互联网上的文本,但物理AI必须具备机器东说念主的第一东说念主称视角,而宇宙上大部分视频数据是第三东说念主称的。咱们通过遥操作主说念主类演示启动,期骗Omniverse进行模拟,并并吞强化学习的可考证奖励来指点物理AI模子。这么咱们能从第三东说念主称视角学习并重新投影到第一东说念主称视角,最终领有一个宇宙基础模子。
今天咱们认真发布Cosmos-3,这是物理AI的前沿基础模子。当你想要创建任何触及物理宇宙的机器东说念主时,Cosmos-3不错看成伴侣。它或者知道、推理并生成动作,不错在轮回中进行模拟致使看成政策本人。
现实宇宙是无穷且不可展望的,物理AI需要数据但现实数据无法完结范围化,因此对于物理AI而言算力即数据。Cosmos是一个面向物理AI的开放前沿万能模子,基于全新的羼杂Transformer架构构建。像素、动作、声息和言语流入自追思Transformer,它对扩散Transformer进行推理、计议和指示指点。开发者不错针对不同具体态态和场景对Cosmos进行后期检会。
看成视觉言语模子,Cosmos不雅察物理宇宙并知道场景;看成宇宙模子,它能生成适应物理法例的合成视频;看成模拟器,它为政策检会和评估完结闭环。对Cosmos进行后检会后,它便进化为宇宙动作模子,能为千般机器东说念主进行感知、推理、计议并生成动作。咱们开放了模子、数据致使检会表情,让你不错自行增强并将其转动为专有模子。
AI本事栈相配复杂,包含生成器、模子、模拟器和运行时。自动驾驶汽车本质上是一个物理AI智能体机器东说念主,今天咱们晓谕推出AlphaGo 2开源模子。咫尺正在制造NVIDIA Hyperion汽车的厂商占据了全球汽车份额的80%。
咱们也还是接入了移动出行办事,宇宙上大要97%的移动出行办事正在与咱们建立贯穿。当咱们基于Kalos操作系统在Hyperion运行时上部署AlphaGo时,将或者贯穿全球的总共这些办事。AlphaGo是全球首款具备推理能力的自动驾驶汽车。它在行驶中会不停想考,及时计议道路,微调避开静止车辆,在交叉路口和泊车美艳前泊车,何况主动礼让行东说念主与横向车流。
咱们创造的本事相似适用于东说念主形机器东说念主。NVIDIA ISAAC GROOT是咱们的东说念主形机器东说念主本事栈,涵盖了模子、数据生成、仿真、运行时以及操作系统。不管是云霄或PC端的智能体系统,如故自动驾驶汽车与机器东说念主的配合系统,它们的蓄意模式完全交流。咱们垂直且完整地构建了一切,并与共同遐想相集成,然后将其完全开放供每个东说念主使用。为了委派这些参考平台,就像咱们对待PC和自动驾驶汽车那样,咱们咫尺也要为机器东说念主打造参考平台。
今天咱们晓谕推出NVIDIA ISAAC GROOT参考东说念主形机器东说念主。该机器东说念主领有31个开脱度,每只手领有25个开脱度,身高6英尺,体重150磅。
这个平台运行着新的Thor芯片以及咱们总共这个词数据生成和仿真软件栈,全部集成在一个专为开发者遐想的机器东说念主中。它为高级西宾和大学斟酌东说念主员构建,处置了他们从零启动勉强仿真器、遥操作和数据活水线的难题。
ISAAC GROOT提供了开放模子、仿真与检会库、数据生成器和机器东说念主蓄意机,全历程数小时内即可就绪。你不错使用Isaac Lab设立仿真环境,期骗Omniverse和Cosmos生成合成数据,在Isaac Arena中评估政策并在Jetson Thor上部署。
在畴昔的六个月里,蓄意机行业发生了澈底的转换,智能体与最新前沿模子相交融,使得AI咫尺或者从事有用的责任。这种由模子组成的智能体蓄意模式期骗手段调用器具并在运行时中施行,不管在哪种设备上模式王人是交流的。对于这种智能体平台,NVIDIA领有一套Enterprise AI Toolkit,是与AI互动的绝佳表情。
咫尺Vera Rubin正在全力坐褥中。Grace Blackwell是成心为处理AI推理而创造的,而Vera Rubin则是为了运行智能体而创造的完整解耦式、溜达式智能体处理系统。
NVIDIA还是成为一家基础设施公司,致力于匡助客户完结利润最大化。用于智能体的CPU有其特殊需求,立异性的NVIDIA Vera正处于产能爬坡阶段,咫尺的订单量将使其成为公司历史上最快、最得手的居品发布。
NVIDIA和Microsoft创建了一个全新的PC居品线,这种代理式蓄意模式将在全球各地的机器东说念主、卫星、基站、工场以及云霄和边际设备中得到复制。
AI本事就像一块五层蛋糕,全球AI云还是构建了数吉瓦的容量,DSX保持低功耗运行以贯穿每一个要道节点。RTX 4终于到来,这是40年来PC范围最要紧的时刻,智能体将助力总共责任流。模子在GPU上迅速运行,Cosmos构建机器东说念主所需的宇宙,实用的AI期间还是到来尊龙凯时中国官方入口,智能体正与你并肩配合。